第 4 章 处理器
一台计算机的性能由三个关键因素决定:
- 指令数目
- 时钟周期长度
- 每条指令所需时钟周期数(CPI, Clocks per Instruction)
基本的 MIPS 实现 (和 CSAPP 的 x86 不同)
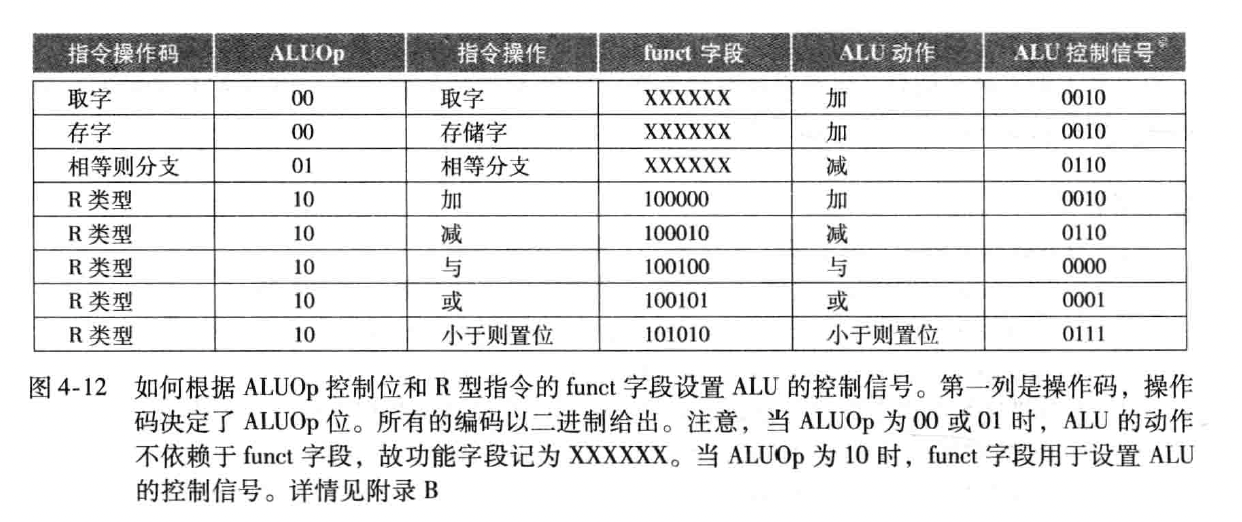
- 存储器访问指令:取字(
lw)、存字(sw) - 算术逻辑指令(R 型指令):加法(
add)、减法(sub)、与运算(AND)或运算(OR)小于则设置(slt) - 分支指令:相等则分支(
beq)、跳转(j) - 没有浮点数、没有乘除指令,但后续可扩展
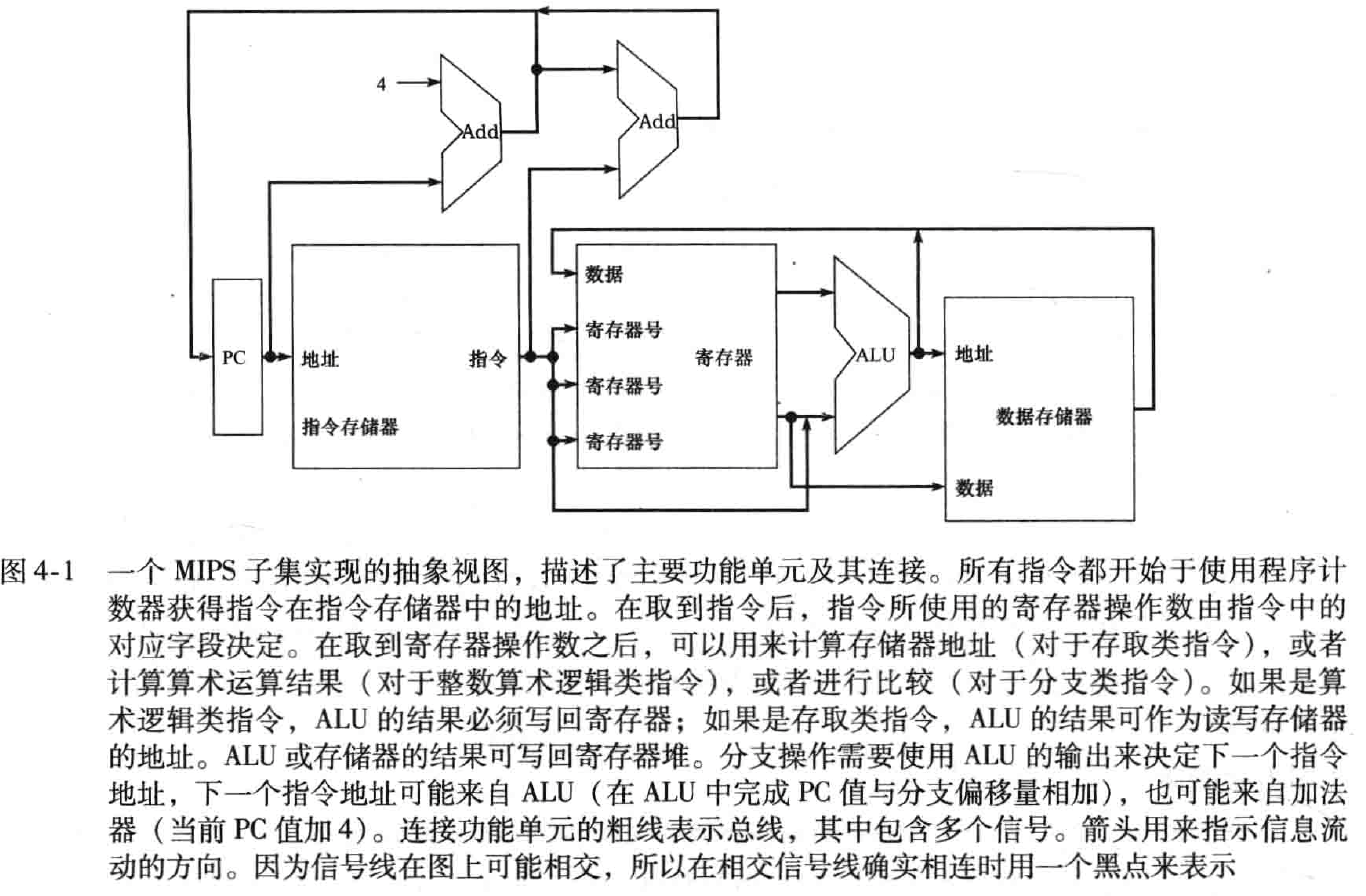
实现方式概述
- 程序计数器(PC)指向指令所在的存储单元,并从中取出指令
- 通过指令字段内容,选择读取一两个寄存器,只有取字指令读一个寄存器
- 之后取决于具体指令类型,但大致相同。存储访问用 ALU 计算地址;算术逻辑用 ALU 执行运算;分支用 ALU 进行比较
流水线冒险
定义:在下一个时钟周期中下一跳指令不能执行
结构冒险:硬件不支持多条指令在同一时钟周期执行。比如第一条指令在访问存储器,第四条指令在预取指令,就会结构冒险
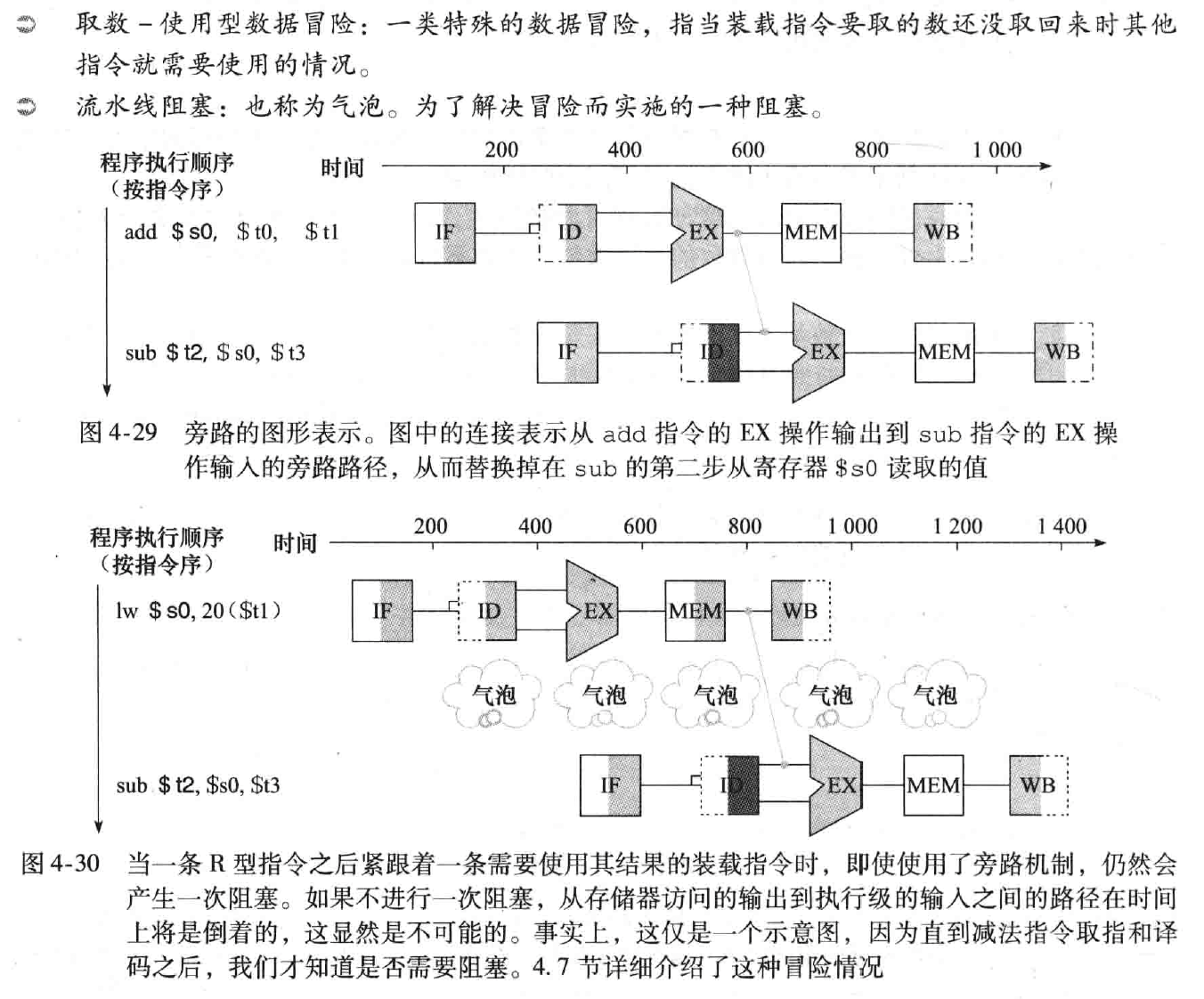
数据冒险:一条指令必须等待另一条执行的完成而造成流水线暂停。有数据依赖时会产生
前推:也称为旁路。是一种解决数据冒险的做法,具体做法是从内部寄存器而非程序员课件的寄存器或存储器中提前取出数据
控制冒险(分支冒险):决策依赖于一条指令的结果,而其他指令正在执行中;因为指令地址的变化并不是流水线所预期的,而导致指令不能在预定的时钟周期内执行
旁路技术
- 取指令阶段(IF):从指令存储器中取出指令。
- 译码阶段(ID):解析指令,读取寄存器文件中的操作数。
- 执行阶段(EX):执行指令的运算部分。
- 访存阶段(MEM):访问数据存储器(如果需要)。
- 写回阶段(WB):将计算结果写回寄存器文件。
假设有以下指令序列:
1 | ADD R1, R2, R3 # R1 = R2 + R3 |
在没有旁路的情况下,第二条指令(SUB)需要等到第一条指令(ADD)完成写回阶段(WB)后,才能读取 R1 的值。这意味着第二条指令会被暂停,直到第一条指令完成。
有了旁路技术,处理器可以在第一条指令的执行阶段(EX)完成后,立即将 R1 的值转发给第二条指令的执行阶段(EX),而不需要等待写回阶段(WB)完成。
分支预测的原因
遇到分支指令时,比如 if 语句或循环,处理器需要知道分支的结果才能确定下一条指令的执行路径。如果处理器在等待分支指令的结果期间停止或延迟其他指令的执行,整个流水线的效率就会大大降低。
乱序发射(Out-of-Order Execution)是一种高级处理器优化技术,通过允许指令不按程序的顺序执行,来提高指令的执行效率和处理器的整体性能。这种技术通过动态地重新排列指令的执行顺序,有效地利用处理器中的可用资源,减少因数据依赖和资源冲突导致的流水线停顿。
乱序发射的工作原理
- 指令取指(Instruction Fetch):处理器按照程序的顺序从内存或指令缓存中取指。
- 指令解码(Instruction Decode):将取出的指令解码,识别操作码、操作数和目标寄存器。
- 指令调度(Instruction Scheduling):在乱序执行的处理器中,这一步骤至关重要。处理器将解码后的指令放入一个称为“指令窗口(Instruction Window)”或“缓冲区(Buffer)”的结构中。指令调度器会分析这些指令之间的依赖关系,并寻找可以无冲突执行的指令。
- 指令发射(Instruction Issue):处理器根据可用的执行单元和指令的准备情况,选择可以立即执行的指令发射到执行单元中。这些指令可能不是按照程序顺序,而是按照资源可用性和依赖性来决定的顺序。
- 指令执行(Instruction Execution):各执行单元并行且独立地执行指令。由于乱序发射,处理器可以在等待某些指令的操作数准备就绪时,继续执行其他不依赖这些操作数的指令。
- 结果提交(Commit/Retire):为了保证程序的最终结果与顺序执行一致,处理器使用一个重排序缓冲区(Reorder Buffer, ROB)来按程序顺序提交指令的执行结果。只有当一个指令的所有前驱指令都提交之后,它的结果才会正式写回寄存器或内存。
乱序发射的优点
- 提高资源利用率:通过动态调度和乱序发射,处理器能够更高效地利用执行单元,减少因等待资源或数据导致的停顿。
- 减少流水线停顿:乱序发射可以在等待数据准备就绪时,继续执行其他不依赖这些数据的指令,减少流水线的停顿时间。
- 提高指令级并行性(ILP):通过允许指令不按顺序执行,处理器能够更充分地挖掘指令级并行性,提高每个时钟周期内执行的指令数量。
乱序发射的挑战
- 复杂性:实现乱序发射需要复杂的硬件支持,包括指令窗口、重排序缓冲区、数据依赖检测逻辑等,这增加了处理器设计和制造的复杂性和成本。
- 功耗和面积:复杂的乱序执行逻辑会增加处理器的功耗和芯片面积,这在移动设备等功耗敏感的应用中尤为关键。
- 正确性保证:乱序执行必须保证最终的程序结果与顺序执行一致,这需要精密的控制和验证机制,以处理各种数据和控制依赖。